动态场景下基于实例分割与运动一致性约束的VSLAM算法
目前传统的同时定位与地图构建(SLAM)算法在动态场景下易出现难以完整标记潜在动态物体和无法准确判断动态物体运动状态等问题,影响相机位姿估计精度。为此,本文提出了一种基于实例分割与运动一致性约束的视觉SLAM(VSLAM)算法。通过设计一种ReT-encoder模块,引导模型关注并提取图像局部特征信息和全局特征信息,同时设计一种混合权重特征金字塔网络(FPN)模块,通过权重系数融合学习大物体特征和小物体特征,精确标记潜在动态物体区域。为进一步减少动态物体对SLAM系统定位精度的影响,通过位姿估计和偏转误差判断物体的运动状态并剔除动态物体。
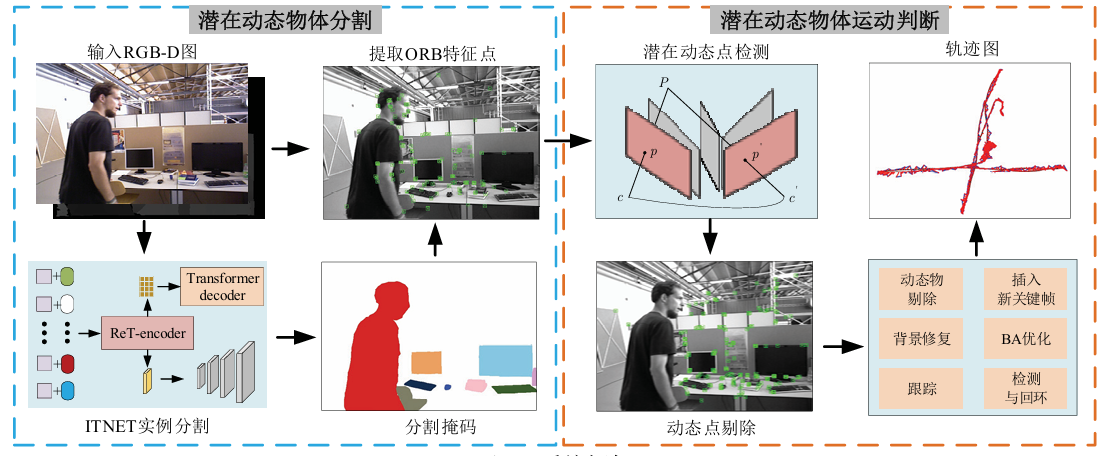
本文算法包含潜在动态物体分割和物体运动状态 判断两个环节。在潜在动态物体分割阶段,通过本文 提出的实例分割网络 ITNET(Improved Transformer Encoder Network for Instance Segmentation)完成潜在 动态物体的实例分割。在潜在物体运动状态判断环节, 通过位姿估计和构建运动状态模型获取物体的偏转误 差,标记动态点并剔除动态物体。IMD-SLAM算法框 图如下图所示。
本文实验所用平台软硬件配置为:CPU为Inter i9 12900K处理器,主频3.2 GHZ,内存16 GB;GPU为 RTX3090显卡,显存24 GB;系统为Ubuntu18.04。深 度学习框架由开源的PyTorch实现。最终在公开数据集TUM和真实场景中进行验证,结果表明所提算法的平均绝对轨迹均方根误差与ORB-SLAM2、 DS-SLAM和DynaSLAM算法相比,分别减少了95.23%、46.85%和15.88%。